쿠버네티스 컴포넌트
쿠버네티스를 배포하면 클러스터를 얻는다.
쿠버네티스 클러스터는 컨테이너화된 애플리케이션을 실행하는 노드라고 하는 워커 머신의 집합. 모든 클러스터는 최소 한 개의 워커 노드를 가진다.
워커 노드는 애플리케이션의 구성요소인 파드가장 작고 단순한 쿠버네티스 오브젝트. 파드는 사용자 클러스터에서 동작하는 컨테이너의 집합을 나타낸다. 를 호스트한다. 컨트롤 플레인컨테이너의 라이프사이클을 정의, 배포, 관리하기 위한 API와 인터페이스들을 노출하는 컨테이너 오케스트레이션 레이어. 은 워커 노드와 클러스터 내 파드를 관리한다. 프로덕션 환경에서는 일반적으로 컨트롤 플레인이 여러 컴퓨터에 걸쳐 실행되고, 클러스터는 일반적으로 여러 노드를 실행하므로 내결함성과 고가용성이 제공된다.
이 문서는 완전히 작동하는 쿠버네티스 클러스터를 갖기 위해 필요한 다양한 컴포넌트들에 대해 요약하고 정리한다.
여기에 모든 컴포넌트가 함께 있는 쿠버네티스 클러스터 다이어그램이 있다.
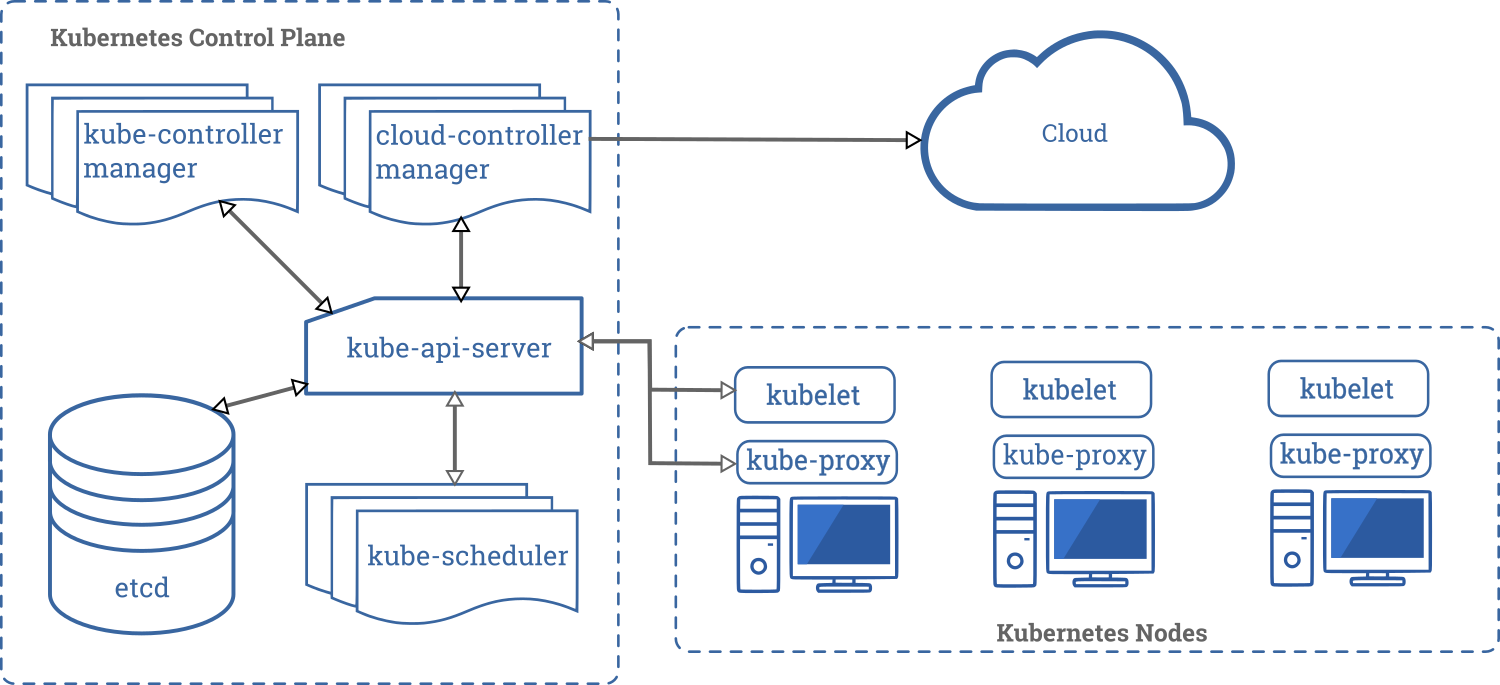
컨트롤 플레인 컴포넌트
컨트롤 플레인 컴포넌트는 클러스터에 관한 전반적인 결정(예를 들어, 스케줄링)을 수행하고 클러스터 이벤트(예를 들어, 디플로이먼트의 replicas 필드에 대한 요구 조건이 충족되지 않을 경우 새로운 파드가장 작고 단순한 쿠버네티스 오브젝트. 파드는 사용자 클러스터에서 동작하는 컨테이너의 집합을 나타낸다.
를 구동시키는 것)를 감지하고 반응한다.
컨트롤 플레인 컴포넌트는 클러스터 내 어떠한 머신에서든지 동작할 수 있다. 그러나 간결성을 위하여, 구성 스크립트는 보통 동일 머신 상에 모든 컨트롤 플레인 컴포넌트를 구동시키고, 사용자 컨테이너는 해당 머신 상에 동작시키지 않는다. 다중-마스터-VM 설치 예제를 보려면 고가용성 클러스터 구성하기를 확인해본다.
kube-apiserver
API 서버는 쿠버네티스 API를 노출하는 쿠버네티스 컨트롤 플레인컨테이너의 라이프사이클을 정의, 배포, 관리하기 위한 API와 인터페이스들을 노출하는 컨테이너 오케스트레이션 레이어. 컴포넌트이다. API 서버는 쿠버네티스 컨트롤 플레인의 프론트 엔드이다.
쿠버네티스 API 서버의 주요 구현은 kube-apiserver 이다. kube-apiserver는 수평으로 확장되도록 디자인되었다. 즉, 더 많은 인스턴스를 배포해서 확장할 수 있다. 여러 kube-apiserver 인스턴스를 실행하고, 인스턴스간의 트래픽을 균형있게 조절할 수 있다.
etcd
모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 저장소로 사용되는 일관성·고가용성 키-값 저장소.
쿠버네티스 클러스터에서 etcd를 뒷단의 저장소로 사용한다면, 이 데이터를 백업하는 계획은 필수이다.
etcd에 대한 자세한 정보는, 공식 문서를 참고한다.
kube-scheduler
노드노드는 쿠버네티스의 작업 장비(worker machine)이다. 가 배정되지 않은 새로 생성된 파드가장 작고 단순한 쿠버네티스 오브젝트. 파드는 사용자 클러스터에서 동작하는 컨테이너의 집합을 나타낸다. 를 감지하고, 실행할 노드를 선택하는 컨트롤 플레인 컴포넌트.
스케줄링 결정을 위해서 고려되는 요소는 리소스에 대한 개별 및 총체적 요구 사항, 하드웨어/소프트웨어/정책적 제약, 어피니티(affinity) 및 안티-어피니티(anti-affinity) 명세, 데이터 지역성, 워크로드-간 간섭, 데드라인을 포함한다.
kube-controller-manager
컨트롤러API 서버를 통해 클러스터의 공유된 상태를 감시하고, 현재 상태를 원하는 상태로 이행시키는 컨트롤 루프. 를 구동하는 마스터 상의 컴포넌트.
논리적으로, 각 컨트롤러API 서버를 통해 클러스터의 공유된 상태를 감시하고, 현재 상태를 원하는 상태로 이행시키는 컨트롤 루프. 는 개별 프로세스이지만, 복잡성을 낮추기 위해 모두 단일 바이너리로 컴파일되고 단일 프로세스 내에서 실행된다.
이들 컨트롤러는 다음을 포함한다.
- 노드 컨트롤러: 노드가 다운되었을 때 통지와 대응에 관한 책임을 가진다.
- 레플리케이션 컨트롤러: 시스템의 모든 레플리케이션 컨트롤러 오브젝트에 대해 알맞은 수의 파드들을 유지시켜 주는 책임을 가진다.
- 엔드포인트 컨트롤러: 엔드포인트 오브젝트를 채운다(즉, 서비스와 파드를 연결시킨다.)
- 서비스 어카운트 & 토큰 컨트롤러: 새로운 네임스페이스에 대한 기본 계정과 API 접근 토큰을 생성한다.
cloud-controller-manager
cloud-controller-manager는 바탕을 이루는 클라우드 제공사업자와 상호작용하는 컨트롤러를 작동시킨다. cloud-controller-manager 바이너리는 쿠버네티스 릴리스 1.6에서 도입된 알파 기능이다.
cloud-controller-manager는 클라우드-제공사업자-특유 컨트롤러 루프만을 동작시킨다. 이 컨트롤러 루프는 kube-controller-manager에서 비활성 시켜야만 한다. kube-controller-manager를 구동시킬 때 --cloud-provider 플래그를 external로 설정함으로써 이 컨트롤러 루프를 비활성 시킬 수 있다.
cloud-controller-manager는 클라우드 벤더 코드와 쿠버네티스 코드가 서로 독립적으로 발전시켜 나갈 수 있도록 해준다. 이전 릴리스에서는 코어 쿠버네티스 코드가 기능상으로 클라우드-제공사업자-특유 코드에 대해 의존적이었다. 향후 릴리스에서 클라우드 벤더만의 코드는 클라우드 벤더가 유지해야 하며, 쿠버네티스가 동작하는 동안 cloud-controller-manager에 연계되도록 해야 한다.
다음 컨트롤러들은 클라우드 제공사업자의 의존성을 갖는다.
- 노드 컨트롤러: 노드가 응답을 멈춘 후 클라우드 상에서 삭제되었는지 판별하기 위해 클라우드 제공사업자에게 확인하는 것
- 라우트 컨트롤러: 기본 클라우드 인프라에 경로를 구성하는 것
- 서비스 컨트롤러: 클라우드 제공사업자 로드밸런서를 생성, 업데이트 그리고 삭제하는 것
- 볼륨 컨트롤러: 볼륨의 생성, 연결 그리고 마운트 하는 것과 오케스트레이션하기 위해 클라우드 제공사업자와 상호작용하는 것
노드 컴포넌트
노드 컴포넌트는 동작 중인 파드를 유지시키고 쿠버네티스 런타임 환경을 제공하며, 모든 노드 상에서 동작한다.
kubelet
클러스터의 각 노드노드는 쿠버네티스의 작업 장비(worker machine)이다. 에서 실행되는 에이전트. Kubelet은 파드가장 작고 단순한 쿠버네티스 오브젝트. 파드는 사용자 클러스터에서 동작하는 컨테이너의 집합을 나타낸다. 에서 컨테이너소프트웨어와 그것에 종속된 모든 것을 포함한 가볍고 휴대성이 높은 실행 가능 이미지. 가 확실하게 동작하도록 관리한다.
Kubelet은 다양한 메커니즘을 통해 제공된 파드 스펙(PodSpec)의 집합을 받아서 컨테이너가 해당 파드 스펙에 따라 건강하게 동작하는 것을 확실히 한다. Kubelet은 쿠버네티스를 통해 생성되지 않는 컨테이너는 관리하지 않는다.
kube-proxy
kube-proxy는 클러스터의 각 노드노드는 쿠버네티스의 작업 장비(worker machine)이다. 에서 실행되는 네트워크 프록시로, 쿠버네티스의 서비스네트워크 서비스로 파드 집합에서 실행 중인 애플리케이션을 노출하는 방법 개념의 구현부이다.
kube-proxy는 노드의 네트워크 규칙을 유지 관리한다. 이 네트워크 규칙이 내부 네트워크 세션이나 클러스터 바깥에서 파드로 네트워크 통신을 할 수 있도록 해준다.
kube-proxy는 운영 체제에 가용한 패킷 필터링 계층이 있는 경우, 이를 사용한다. 그렇지 않으면, kube-proxy는 트래픽 자체를 포워드(forward)한다.
컨테이너 런타임
컨테이너 런타임은 컨테이너 실행을 담당하는 소프트웨어이다.
쿠버네티스는 여러 컨테이너 런타임을 지원한다. 도커(Docker)Docker는 운영 시스템 수준의 가상화를 제공하는 소프트웨어 기술이며, 컨테이너로도 알려져 있다. , containerdA container runtime with an emphasis on simplicity, robustness and portability , CRI-OA lightweight container runtime specifically for Kubernetes 그리고 Kubernetes CRI (컨테이너 런타임 인터페이스)를 구현한 모든 소프트웨어.
애드온
애드온은 쿠버네티스 리소스(데몬셋파드의 복제본을 클러스터 노드 집합에서 동작하게 한다.
,
디플로이먼트복제된(replicated) 애플리케이션을 관리하는 API 오브젝트.
등)를
이용하여 클러스터 기능을 구현한다. 이들은 클러스터 단위의 기능을 제공하기 때문에
애드온에 대한 네임스페이스 리소스는 kube-system 네임스페이스에 속한다.
선택된 일부 애드온은 아래에 설명하였고, 사용 가능한 전체 확장 애드온 리스트는 애드온을 참조한다.
DNS
여타 애드온들이 절대적으로 요구되지 않지만, 많은 예시에서 필요로 하기 때문에 모든 쿠버네티스 클러스터는 클러스터 DNS를 갖추어야만 한다.
클러스터 DNS는 구성환경 내 다른 DNS 서버와 더불어, 쿠버네티스 서비스를 위해 DNS 레코드를 제공해주는 DNS 서버다.
쿠버네티스에 의해 구동되는 컨테이너는 DNS 검색에서 이 DNS 서버를 자동으로 포함한다.
웹 UI (대시보드)
대시보드는 쿠버네티스 클러스터를 위한 범용의 웹 기반 UI다. 사용자가 클러스터 자체뿐만 아니라, 클러스터에서 동작하는 애플리케이션에 대한 관리와 문제 해결을 할 수 있도록 해준다.
컨테이너 리소스 모니터링
컨테이너 리소스 모니터링은 중앙 데이터베이스 내의 컨테이너들에 대한 포괄적인 시계열 매트릭스를 기록하고 그 데이터를 열람하기 위한 UI를 제공해 준다.
클러스터-레벨 로깅
클러스터-레벨 로깅 메커니즘은 검색/열람 인터페이스와 함께 중앙 로그 저장소에 컨테이너 로그를 저장하는 책임을 진다.
다음 내용
- 노드에 대해 더 배우기
- 컨트롤러에 대해 더 배우기
- kube-scheduler에 대해 더 배우기
- etcd의 공식 문서 읽기
피드백
이 페이지가 도움이 되었나요?
피드백 감사합니다. 쿠버네티스 사용 방법에 대해서 구체적이고 답변 가능한 질문이 있다면, 다음 링크에서 질문하십시오. Stack Overflow. 원한다면 GitHub 리포지터리에 이슈를 열어서 문제 리포트 또는 개선 제안이 가능합니다..
최종 수정일시 March 26, 2020 at 10:58 PM PST , 다음 변경에 의해서:
Seventh Korean l10n Work For Release 1.17 (#19858) (페이지 변경 이력)